
یادگیری ماشین انسانمحور(Human-Centered Machine Learning)
- UX/UI تجربه کاربری طراحی رابط کاربری طراحی محصول مدرسه هوشمصنوعی
- بروزرسانی شده در
")
۷ گام برای متمرکز ماندن بر کاربر هنگام طراحی با یادگیری ماشین
یادگیری ماشین (ML) علم کمک به کامپیوترها برای کشف الگوها و روابط در دادهها به جای برنامهنویسی دستی است. این ابزاری قدرتمند برای خلق تجربیات شخصیسازیشده و پویا است و در حال حاضر همه چیز را، از توصیههای نتفلیکس گرفته تا خودروهای خودران، به پیش میبرد. اما با افزایش تجربیاتی که با یادگیری ماشین ساخته میشوند، واضح است که متخصصان تجربه کاربری (UX) هنوز باید چیزهای زیادی بیاموزند تا به کاربران کمک کنند احساس کنند کنترل این فناوری را در دست دارند، نه برعکس.
آنچه در این مقاله میخوانید
همانند انقلاب موبایل و پیش از آن، وب، یادگیری ماشین باعث خواهد شد تا ما تقریباً در مورد تمام تجربیاتی که میسازیم، بازاندیشی کنیم، ساختارها را تغییر دهیم، جابجایی ایجاد کنیم و امکانات جدیدی را در نظر بگیریم. در جامعه تجربه کاربری گوگل، ما تلاشی را با عنوان «یادگیری ماشین انسان-محور» (HCML) آغاز کردهایم تا به تمرکز و هدایت این گفتگو کمک کنیم. با استفاده از این دیدگاه، ما محصولات مختلف را بررسی میکنیم تا ببینیم چگونه یادگیری ماشین میتواند ریشه در نیازهای انسانی داشته باشد و در عین حال، این نیازها را به شیوههایی منحصربهفرد که تنها از طریق ML ممکن است، حل کند. تیم ما در گوگل با متخصصان تجربه کاربری در سراسر شرکت همکاری میکند تا آنها را با مفاهیم اصلی یادگیری ماشین آشنا سازد، به آنها در درک نحوه ادغام ML در جعبه ابزار UX کمک کند و اطمینان حاصل نماید که یادگیری ماشین و هوش مصنوعی (AI) به شیوهای فراگیر ساخته میشوند.
اگر به تازگی کار با یادگیری ماشین را آغاز کردهاید، ممکن است کمی تحت تأثیر پیچیدگی این فضا و گستردگی فرصتهای نوآوری قرار گرفته باشید. آرام باشید، به خودتان زمان دهید تا با فضا آشنا شوید و نگران نباشید. نیازی نیست برای اینکه در تیم خود فرد باارزشی باشید، خودتان را از نو بسازید.
ما هفت نکته را تدوین کردهایم تا به طراحان در پیمایش این عرصه جدید، یعنی طراحی محصولات مبتنی بر یادگیری ماشین، کمک کنیم. این نکات که از دلِ کار ما با تیمهای تجربه کاربری و هوش مصنوعی در گوگل (و مقدار زیادی آزمون و خطا) بیرون آمدهاند، به شما کمک میکنند تا کاربر را در اولویت قرار دهید، به سرعت تکرار کنید و فرصتهای منحصربهفردی را که یادگیری ماشین ایجاد میکند، درک نمایید.
بیایید شروع کنیم.
۱. انتظار نداشته باشید که یادگیری ماشین بفهمد چه مشکلاتی را باید حل کند
در حال حاضر هیاهوی زیادی پیرامون یادگیری ماشین و هوش مصنوعی وجود دارد. بسیاری از شرکتها و تیمهای محصول، مستقیماً به سراغ استراتژیهای محصولی میروند که با ML به عنوان یک راهحل شروع میشوند و از تمرکز بر یک مشکل معنادار برای حل کردن، عبور میکنند.

این رویکرد برای اکتشاف محض یا دیدن تواناییهای یک فناوری خوب است و اغلب الهامبخش تفکر محصول جدید میشود. با این حال، اگر با یک نیاز انسانی همسو نباشید، در نهایت یک سیستم بسیار قدرتمند برای حل یک مشکل بسیار کوچک — یا شاید غیرموجود — خواهید ساخت.
بنابراین نکته اول ما این است که شما هنوز هم باید تمام آن کارهای سختی را که همیشه برای یافتن نیازهای انسانی انجام میدادید، انجام دهید. این کارها شامل مردمنگاری، تحقیقات میدانی، مصاحبهها، معاشرت عمیق، نظرسنجیها، خواندن تیکتهای پشتیبانی مشتری، تحلیل لاگها و نزدیک شدن به مردم برای فهمیدن این است که آیا در حال حل یک مشکل هستید یا به یک نیاز بیاننشدهی آنها پاسخ میدهید. یادگیری ماشین قرار نیست بفهمد چه مشکلاتی را باید حل کند. ما هنوز باید آن را تعریف کنیم. به عنوان متخصصان تجربه کاربری، ما از قبل ابزارهای لازم برای هدایت تیمهایمان را در اختیار داریم، صرفنظر از پارادایم فناوری غالب.
۲. از خود بپرسید که آیا یادگیری ماشین مشکل را به شیوهای منحصربهفرد حل میکند
هنگامی که نیاز یا نیازهایی را که میخواهید به آنها پاسخ دهید شناسایی کردید، باید ارزیابی کنید که آیا یادگیری ماشین میتواند این نیازها را به شیوههایی منحصربهفرد حل کند یا خیر. مشکلات قانونی و معتبر زیادی وجود دارند که به راهحلهای ML نیازی ندارند.
یک چالش در این مرحله از توسعه محصول، تعیین این است که کدام تجربیات به ML نیاز دارند، کدامها به طور معناداری با ML بهبود مییابند، و کدامها از ML سودی نمیبرند یا حتی کیفیتشان با آن کاهش مییابد. بسیاری از محصولات میتوانند بدون ML «هوشمند» یا «شخصی» به نظر برسند. فریب این تفکر را نخورید که این ویژگیها تنها با یادگیری ماشین ممکن هستند.
ما مجموعهای از تمرینها را ایجاد کردهایم تا به تیمها کمک کنیم ارزش ML را برای موارد استفاده خود درک کنند. این تمرینها با بررسی جزئیات مدلهای ذهنی و انتظاراتی که افراد ممکن است هنگام تعامل با یک سیستم ML داشته باشند و همچنین دادههای مورد نیاز برای آن سیستم، این کار را انجام میدهند.
در اینجا سه تمرین نمونه آورده شده است که از تیمها میخواهیم در مورد موارد استفادهای که قصد دارند با ML حل کنند، به آنها پاسخ دهند:
- روشی را که یک «متخصص» انسانی فرضی ممکن است امروز این کار را انجام دهد، توصیف کنید.
- اگر متخصص انسانی شما این کار را انجام میداد، چگونه به او پاسخ میدادید تا برای دفعه بعد بهتر عمل کند؟ این کار را برای هر چهار فاز ماتریس درهمریختگی (confusion matrix) انجام دهید.
- اگر یک انسان این کار را انجام میداد، کاربر چه انتظاراتی از او داشت که مفروض بگیرد؟
صرف تنها چند دقیقه برای پاسخ به هر یک از این سؤالات، فرضیات خودکاری را که افراد در مورد یک محصول مبتنی بر ML خواهند داشت، آشکار میکند. این پرسشها هم به عنوان محرکی برای بحث در تیم محصول و هم به عنوان انگیزهای در تحقیقات کاربری، به یک اندازه خوب هستند. ما کمی بعدتر، وقتی به فرآیند تعریف برچسبها و آموزش مدلها بپردازیم، دوباره به این موارد اشاره خواهیم کرد.
پس از این تمرینها و کمی طراحی و داستانپردازی بیشتر برای محصولات و ویژگیهای خاص، ما تمام ایدههای محصول تیم را در یک ماتریس ۲×۲ کاربردی رسم میکنیم:

این کار به ما امکان میدهد تا ایدههای تأثیرگذار را از ایدههای کمتأثیر جدا کنیم و همچنین ببینیم کدام ایدهها به ML وابسته هستند و کدامها نیستند یا ممکن است فقط کمی از آن سود ببرند. شما از قبل باید در این گفتگوها با بخش مهندسی همکاری داشته باشید، اما اگر ندارید، این زمان بسیار خوبی است تا آنها را برای ارزیابی واقعیتهای ML در این ایدهها وارد کنید. هر چیزی که بیشترین تأثیر را بر کاربر داشته باشد و به طور منحصربهفرد توسط ML فعال شود (در گوشه بالا سمت راست ماتریس فوق) همان چیزی است که باید ابتدا روی آن تمرکز کنید.
۳. با نمونههای شخصی و روش جادوگر (Wizard) آن را شبیهسازی کنید
یک چالش بزرگ در سیستمهای ML، ساخت نمونه اولیه (Prototyping) است. اگر تمام ارزش محصول شما این است که از دادههای منحصربهفرد کاربر برای تطبیق یک تجربه با او استفاده میکند، نمیتوانید به سرعت یک نمونه اولیه از آن بسازید و انتظار داشته باشید که حس واقعی داشته باشد. همچنین، اگر منتظر بمانید تا یک سیستم ML کاملاً ساختهشده برای آزمایش طرح در دسترس باشد، احتمالاً برای ایجاد تغییرات معنادار پس از آزمایش، خیلی دیر خواهد بود. با این حال، دو رویکرد تحقیق کاربری وجود دارد که میتواند کمک کند: استفاده از نمونههای شخصی شرکتکنندگان و مطالعات «ویزارد آو آز» (Wizard of Oz).
هنگام انجام تحقیقات کاربری با طرحهای اولیه، از شرکتکنندگان بخواهید برخی از دادههای شخصی خود را — مانند عکسهای شخصی، لیست مخاطبین، یا توصیههای فیلم و موسیقی که دریافت کردهاند — به جلسات بیاورند. به یاد داشته باشید، باید اطمینان حاصل کنید که شرکتکنندگان را به طور کامل در مورد نحوه استفاده از این دادهها در طول آزمایش و زمان حذف آنها مطلع کردهاید. این کار حتی میتواند نوعی «تکلیف» سرگرمکننده برای شرکتکنندگان قبل از جلسه باشد (بالاخره مردم دوست دارند در مورد فیلمهای مورد علاقه خود صحبت کنند).
با این نمونهها، میتوانید پاسخهای درست و غلط سیستم را شبیهسازی کنید. برای مثال، میتوانید شبیهسازی کنید که سیستم یک توصیه فیلم اشتباه به کاربر ارائه میدهد تا ببینید او چگونه واکنش نشان میدهد و چه فرضیاتی در مورد دلیل ارائه آن نتیجه توسط سیستم دارد. این کار به شما کمک میکند تا هزینه و فایده این احتمالات را با اعتبار بسیار بیشتری نسبت به استفاده از نمونههای ساختگی یا توضیحات مفهومی ارزیابی کنید.
رویکرد دومی که برای آزمایش محصولات ML که هنوز ساخته نشدهاند بسیار خوب عمل میکند، انجام مطالعات ویزارد آو آز است. این مطالعات که زمانی بسیار محبوب بودند، در ۲۰ سال گذشته به عنوان یک روش تحقیق کاربری از اهمیتشان کاسته شد. خب، آنها دوباره بازگشتهاند.
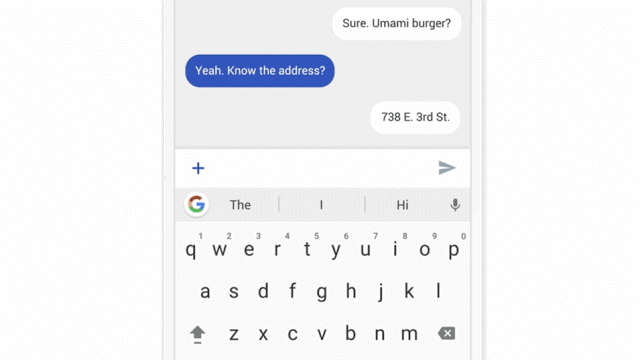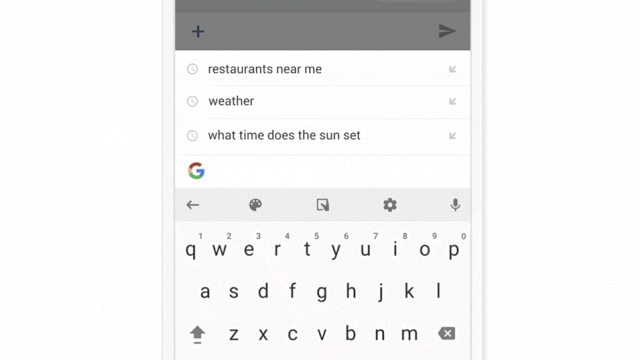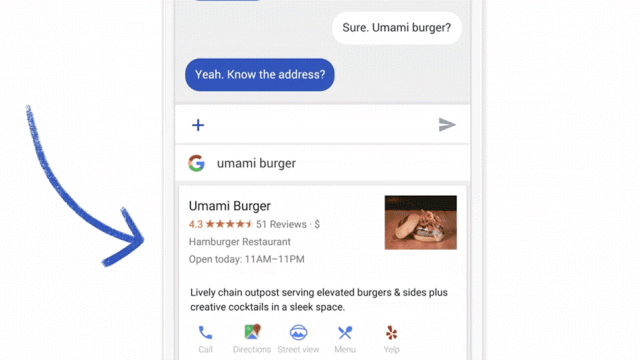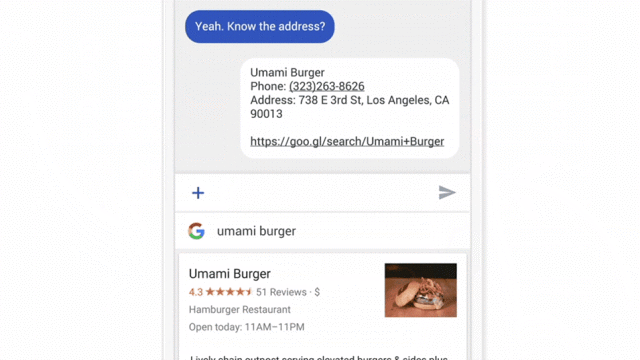
یادآوری سریع: در مطالعات ویزارد آو آز، شرکتکنندگان با سیستمی تعامل دارند که فکر میکنند خودکار است، اما در واقع توسط یک انسان (معمولاً یک همتیمی) کنترل میشود.
اینکه یک همتیمی اقدامات یک سیستم ML مانند پاسخهای چت، پیشنهاد افرادی که شرکتکننده باید با آنها تماس بگیرد، یا پیشنهاد فیلم را تقلید کند، میتواند تعامل با یک سیستم «هوشمند» را شبیهسازی کند. این تعاملات برای هدایت طراحی ضروری هستند. وقتی شرکتکنندگان میتوانند صادقانه با چیزی که آن را یک هوش مصنوعی میپندارند تعامل کنند، به طور طبیعی تمایل پیدا میکنند که یک مدل ذهنی از سیستم تشکیل دهند. پس رفتار خود را بر اساس آن مدلها تنظیم میکنند. مشاهده انطباقها و تعاملات ثانویه آنها با سیستم، برای اطلاعرسانی به طراحی آن بسیار ارزشمند است.
۴. هزینههای مثبتهای کاذب و منفیهای کاذب را بسنجید
سیستم ML شما اشتباه خواهد کرد. مهم است که بفهمید این خطاها چگونه به نظر میرسند و چگونه ممکن است بر تجربه کاربر از محصول تأثیر بگذارند. در یکی از سؤالات نکته ۲ به چیزی به نام ماتریس درهمریختگی اشاره کردیم. این یک مفهوم کلیدی در ML است و توصیف میکند که وقتی یک سیستم ML درست و غلط عمل میکند، چه شکلی دارد.
[توضیحات تصویر: چهار ربع یک ماتریس درهمریختگی. مثبت واقعی: سیستم یک پیشبینی صحیح انجام میدهد. مثبت کاذب: سیستم فکر میکند چیزی را پیدا کرده اما اشتباه میکند. منفی کاذب: سیستم چیزی را که باید پیدا میکرد، از دست میدهد. منفی واقعی: سیستم به درستی چیزی را رد میکند. متن: چهار حالت یک ماتریس درهمریختگی و معنای احتمالی آنها برای کاربران شما.]
در حالی که همه خطاها برای یک سیستم ML یکسان هستند، همه خطاها برای همه افراد یکسان نیستند. برای مثال، اگر یک طبقهبند «آیا این یک انسان است یا یک ترول؟» داشته باشیم، آنگاه بهطور تصادفی یک انسان را به عنوان ترول طبقهبندی کردن، برای سیستم فقط یک خطا است. سیستم هیچ درکی از توهین به کاربر یا زمینه فرهنگی پیرامون طبقهبندیهایی که انجام میدهد، ندارد. نمیفهمد که افرادی که از سیستم استفاده میکنند ممکن است از اینکه به اشتباه برچسب ترول بخورند بسیار بیشتر ناراحت شوند تا اینکه ترولها به اشتباه برچسب انسان بخورند. اما شاید این هم از تعصب انسان-محور ما ناشی میشود. 🙂
در اصطلاحات ML، شما باید مصالحههای آگاهانهای بین دقت (precision) و بازیابی (recall) سیستم انجام دهید. یعنی باید تصمیم بگیرید که آیا مهمتر است که تمام پاسخهای صحیح را شامل شوید حتی اگر به قیمت وارد کردن پاسخهای غلط بیشتر باشد (بهینهسازی برای بازیابی)، یا اینکه تعداد پاسخهای غلط را به قیمت کنار گذاشتن برخی از پاسخهای صحیح به حداقل برسانید (بهینهسازی برای دقت). برای مثال، اگر در Google Photos به دنبال «زمین بازی» بگردید، ممکن است نتایجی مانند این را ببینید:


این نتایج شامل چند صحنه از کودکان در حال بازی است، اما نه در یک زمین بازی. در این مورد، بازیابی بر دقت اولویت دارد. مهمتر است که تمام عکسهای زمین بازی را به دست آوریم و چند عکس مشابه اما نه دقیقاً درست را هم شامل شویم، تا اینکه فقط عکسهای زمین بازی را نشان دهیم و به طور بالقوه عکسی را که به دنبالش بودید، از دست بدهیم.
۵. برای یادگیری مشترک و انطباق برنامهریزی کنید
ارزشمندترین سیستمهای ML در طول زمان به موازات مدلهای ذهنی کاربران تکامل مییابند. وقتی افراد با این سیستمها تعامل میکنند، بر روی انواع خروجیهایی که در آینده خواهند دید تأثیر میگذارند و آنها را تنظیم میکنند. این تنظیمات به نوبه خود نحوه تعامل کاربران با سیستم را تغییر میدهد، که این نیز مدلها را تغییر خواهد داد… و این چرخه بازخورد ادامه مییابد. این میتواند منجر به «تئوریهای توطئه» شود که در آن افراد مدلهای ذهنی نادرست یا ناقصی از یک سیستم تشکیل میدهند و در تلاش برای دستکاری خروجیها بر اساس این قوانین خیالی، با مشکل مواجه میشوند. شما باید کاربران را با مدلهای ذهنی واضح راهنمایی کنید که آنها را تشویق به ارائه بازخوردی کند که هم برای آنها و هم برای مدل سودمند باشد.

سیستمهای یادگیری ماشین بر روی مجموعه دادههای موجود آموزش میبینند. اما وقتی ورودیهای جدید دریافت میکنند، به روشهایی سازگار میشوند که اغلب پیشبینی آنها قبل از وقوع ممکن نیست.
بنابراین ما باید استراتژیهای تحقیق کاربری و بازخورد خود را بر این اساس تطبیق دهیم. این به معنای برنامهریزی قبلی در چرخه محصول برای تحقیقات طولی، با تعامل بالا و همچنین با دسترسی گسترده است. شما باید زمان کافی برای ارزیابی عملکرد سیستمهای ML از طریق معیارهای کمی دقت و خطا با افزایش کاربران و موارد استفاده، و همچنین نشستن با افراد هنگام استفاده از این سیستمها برای درک چگونگی تکامل مدلهای ذهنی با هر موفقیت و شکست، در نظر بگیرید.
علاوه بر این، به عنوان متخصصان تجربه کاربری، ما باید به این فکر کنیم که چگونه میتوانیم بازخورد آنی (in situ) از کاربران در طول کل چرخه عمر محصول برای بهبود سیستمهای ML دریافت کنیم. طراحی الگوهای تعاملی که ارائه بازخورد را آسان میکند و همچنین مزایای آن بازخورد را به سرعت نشان میدهد، شروع به متمایز کردن سیستمهای ML خوب از سیستمهای عالی خواهد کرد.


۶. الگوریتم خود را با استفاده از برچسبهای درست آموزش دهید
به عنوان متخصصان تجربه کاربری، ما به وایرفریمها، ماکاپها، نمونههای اولیه و خطوط راهنما به عنوان خروجیهای شاخص خود عادت کردهایم. خب، یک غافلگیری: وقتی صحبت از تجربه کاربری تقویتشده با ML میشود، چیز زیادی نیست که بتوانیم مشخص کنیم. اینجاست که «برچسبها» وارد میشوند.
برچسبها یک جنبه ضروری از یادگیری ماشین هستند. افرادی هستند که شغلشان این است که به حجم زیادی از محتوا نگاه کرده و آن را برچسبگذاری کنند و به سؤالاتی مانند «آیا در این عکس گربه وجود دارد؟» پاسخ دهند. و هنگامی که تعداد کافی عکس با برچسب «گربه» یا «نه گربه» برچسبگذاری شد، شما یک مجموعه داده دارید که میتوانید از آن برای آموزش یک مدل جهت تشخیص گربهها استفاده کنید. یا به عبارت دقیقتر، برای اینکه بتواند با سطح اطمینان مشخصی پیشبینی کند که آیا در عکسی که قبلاً ندیده، گربه وجود دارد یا نه. ساده است، درست است؟

چالش زمانی پیش میآید که شما وارد قلمرویی میشوید که هدف مدل شما پیشبینی چیزی است که ممکن است برای کاربران شما ذهنی به نظر برسد، مانند اینکه آیا یک مقاله را جالب خواهند یافت یا یک پاسخ ایمیل پیشنهادی را معنادار. اما آموزش مدلها زمان زیادی میبرد و برچسبگذاری کامل یک مجموعه داده میتواند به طور غیرقابل قبولی گران باشد، و ناگفته نماند که اشتباه در برچسبها میتواند تأثیر زیادی بر دوام محصول شما داشته باشد.
بنابراین روش کار این است: با ایجاد فرضیات معقول و بحث در مورد آن فرضیات با طیف متنوعی از همکاران شروع کنید. این فرضیات به طور کلی باید به این شکل باشند: «برای کاربران ________ در شرایط ________، فرض میکنیم که ________ را ترجیح میدهند و ________ را نه.» سپس این فرضیات را در سریعترین زمان ممکن در ابتداییترین نمونه اولیه ممکن پیادهسازی کنید تا شروع به جمعآوری بازخورد و تکرار کنید.
کارشناسانی را پیدا کنید که بتوانند بهترین معلمان ممکن برای یادگیرنده ماشینی شما باشند — افرادی با تخصص در حوزهای که به پیشبینیهای شما مربوط است. ما توصیه میکنیم که تعدادی از آنها را استخدام کنید، یا به عنوان راه جایگزین، یکی از اعضای تیم خود را به این نقش تبدیل کنید. ما این افراد را در تیم خود «متخصصان محتوا» مینامیم.
تا این مرحله، شما مشخص کردهاید که کدام فرضیات «درستتر» از بقیه به نظر میرسند. اما قبل از اینکه کار را بزرگ کرده و در جمعآوری و برچسبگذاری دادهها در مقیاس بزرگ سرمایهگذاری کنید، باید یک دور دوم اعتبارسنجی حیاتی را با استفاده از نمونههایی که توسط متخصصان محتوا از دادههای واقعی کاربران گردآوری شدهاند، انجام دهید. کاربران شما باید یک نمونه اولیه با کیفیت بالا را آزمایش کنند و احساس کنند که با یک هوش مصنوعی واقعی در حال تعامل هستند (طبق نکته شماره ۳).
با در دست داشتن این اعتبارسنجی، از متخصصان محتوای خود بخواهید مجموعهی گستردهای از نمونههای دستساز از آنچه میخواهید هوش مصنوعی شما تولید کند، ایجاد کنند. این نمونهها به شما یک نقشه راه برای جمعآوری داده، مجموعهای قوی از برچسبها برای شروع آموزش مدلها، و یک چارچوب برای طراحی پروتکلهای برچسبگذاری در مقیاس بزرگ میدهند.
۷. خانواده تجربه کاربری خود را گسترش دهید؛ یادگیری ماشین یک فرآیند خلاقانه است
به بدترین «بازخورد» مبتنی بر مدیریت ذرهبینی که تا به حال به عنوان یک متخصص تجربه کاربری دریافت کردهاید، فکر کنید. میتوانید آن فردی را تصور کنید که بالای سر شما خم شده و از هر حرکت شما ایراد میگیرد؟ بسیار خب، حالا این تصویر را در ذهن خود نگه دارید… و کاملاً مطمئن شوید که شما برای مهندسان خود اینگونه به نظر نمیرسید.
راههای بالقوه زیادی برای نزدیک شدن به هر چالش ML وجود دارد، بنابراین به عنوان یک متخصص تجربه کاربری، بیش از حد تجویزی عمل کردن در مراحل اولیه ممکن است به طور ناخواسته باعث جهتدهی — و در نتیجه کاهش خلاقیت — همکاران مهندس شما شود. به آنها اعتماد کنید تا از شهود خود استفاده کنند و آنها را به آزمایش تشویق کنید، حتی اگر ممکن است برای آزمایش با کاربران قبل از اینکه یک چارچوب ارزیابی کامل وجود داشته باشد، مردد باشند.
یادگیری ماشین یک فرآیند مهندسی بسیار خلاقانهتر و بیانگرتر از آن چیزی است که ما عموماً به آن عادت داریم. آموزش یک مدل میتواند کند پیش برود و ابزارهای تجسمسازی هنوز عالی نیستند، بنابراین مهندسان اغلب نیاز دارند هنگام تنظیم یک الگوریتم از تخیل خود استفاده کنند (حتی یک روش به نام «یادگیری فعال» وجود دارد که در آن آنها به صورت دستی مدل را پس از هر تکرار «تنظیم» میکنند). شغل شما این است که به آنها کمک کنید تا در تمام طول مسیر، انتخابهای عالی و کاربر-محور داشته باشند.

پس آنها را با نمونههایی از اینکه یک تجربه شگفتانگیز چگونه میتواند به نظر برسد و چه حسی داشته باشد — از طریق اسلایدها، داستانهای شخصی، ویدئوهای چشمانداز، نمونههای اولیه، کلیپهای تحقیقات کاربری و هر ابزار دیگری — الهام بخشید. تسلط آنها را بر اهداف و یافتههای تحقیقات کاربری افزایش دهید و به آرامی آنها را با دنیای فوقالعادهی ما یعنی نقد طراحی، کارگاهها و اسپرینتهای طراحی آشنا کنید تا به درک عمیقتری از اصول محصول و اهداف تجربه شما کمک کنید. هرچه زودتر با تکرار کردن راحت شوند، برای استحکام خط لوله ML شما و برای توانایی شما در تأثیرگذاری مؤثر بر محصول، بهتر خواهد بود.
نتیجهگیری
اینها هفت نکتهای هستند که ما در گوگل به تیمها تأکید میکنیم. امیدواریم در حین فکر کردن به سؤالات محصولات مبتنی بر ML خودتان، برای شما مفید باشند. با شروع قدرتبخشی یادگیری ماشین به محصولات و تجربیات بیشتر، بیایید به مسئولیت خود برای انسان-محور ماندن، یافتن ارزش منحصربهفرد برای مردم، و عالی ساختن هر تجربهای عمل کنیم.
نویسندگان
جاش لاوجوی یک طراح تجربه کاربری در گروه تحقیقات و هوش ماشینی در گوگل است. او در تقاطع طراحی تعاملی، یادگیری ماشین و آگاهی از سوگیریهای ناخودآگاه کار میکند و طراحی و استراتژی تلاشهای گوگل برای انصاف در ML را رهبری میکند.
جس هولبروک یک مدیر و محقق تجربه کاربری در گروه تحقیقات و هوش ماشینی در گوگل است. او و تیمش بر روی چندین محصول مبتنی بر هوش مصنوعی و یادگیری ماشین کار میکنند که رویکردی انسان-محور به این فناوریها دارند.
تصویرسازیهای زیبا توسط آکیکو اوکازاکی انجام شده است.
ترجمه توسط آکادمی حسین اصلانی انجام شده است.





برای ارسال نظر لطفا ابتدا ثبتنام کنید یا وارد شوید.